在编译型语言中,当使用类似 build 命令进行编译时,在其内部会严格进行内部转换,从编码层转变为机器层(汇编语言),从而使代码赋予的逻辑运行在机器上。但是这一过程对于我们开发者来说是不可见(黑盒)的,接下来从 go build main.go 来解释这其中发生了什么?
引用:
- AST生成: https://pkg.go.dev/go/ast
编译流程概述:
词法分析 -> 语法分析 -> 类型检查 -> AST 到 SSA 转换
在一个 Go 程序被创建时,使用 go build 指令编译后运行二进制文件的过程中,其中经历了多次转换,最终运行在操作系统之上(在Go中,最终编译为汇编语言)
例如我们最熟悉不过的代码,输出 Hello, world(下文所有分析依据于此片段):
package main
import "fmt"
func main() {
fmt.Println("Hello, world")
}
无疑是我们最为常见,但从保存文件到运行,中间做了什么操作,无从得知,得到的只有结果,而中间的过程是不会显示的。
在使用 Go自带的 run 命令后,程序从编译态(Go 为静态语言)到运行态的过程,首先经过编译器,而其主要负责以下操作:
- 构建
AST,此操作为多数语言编译的前提操作,构建抽象语法树。当前阶段主要负责分析、检查和代码生成 - 加载
Runtime运行,主要是在main函数之前加载代码
在执行 build 或者 run 命令后,Go 编译器是怎样进行处理的?
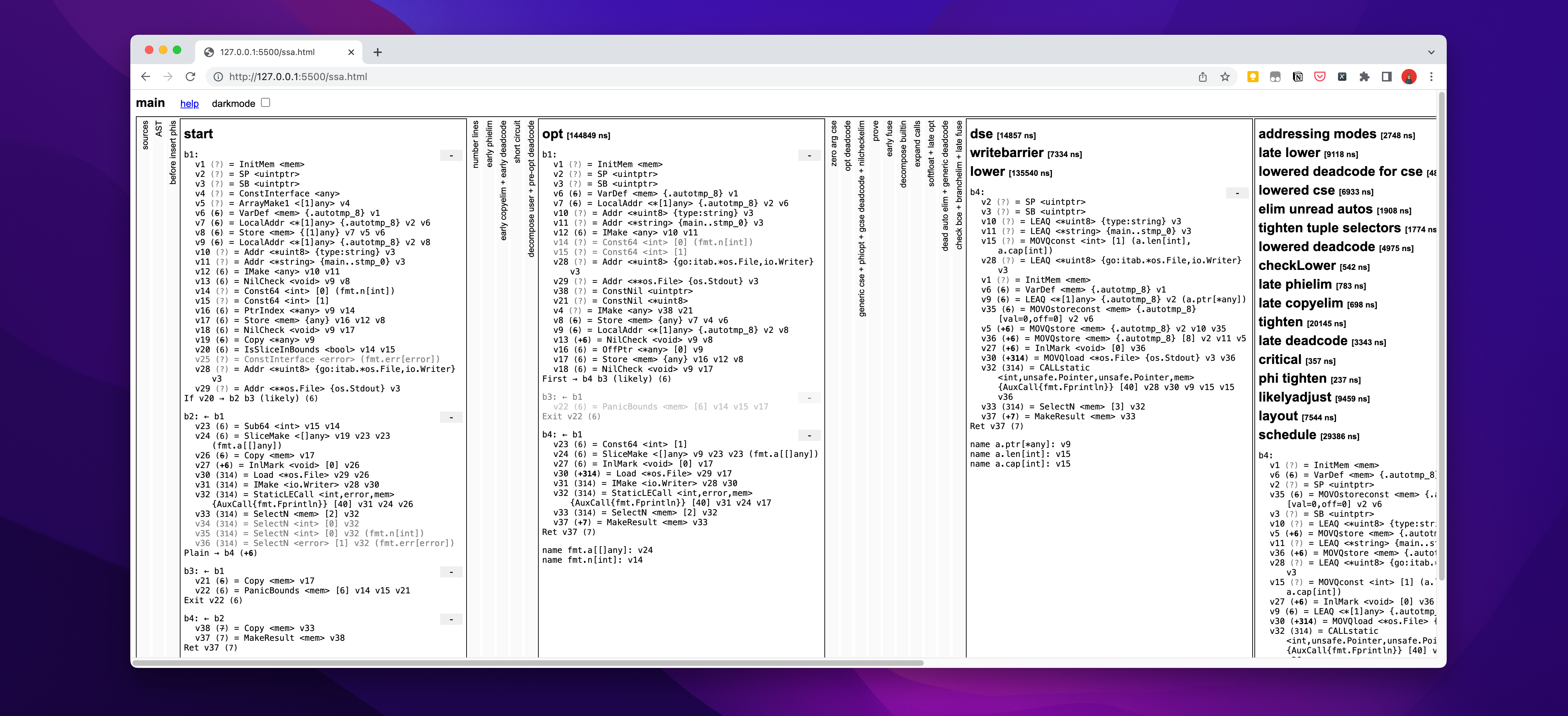
Terminal 中执行命令:GOSSAFUNC=main go build main.go
GOSSAFUNC=main 的意思是:在编译过程中将SSA暴露出来。
命令执行后,会在当前目录下生成文件ssa.html
如下图所示

打开文件在浏览器中显示
一、解析 Go 源码
Go 语言的解析过程主要包括词法分析和语法分析两个阶段。在编译过程中,Go源代码首先会被转换成抽象语法树(AST),然后进行类型检查和代码生成等操作。
1、词法分析
将源码解析为 Token 序列
在词法分析阶段,Go源代码会被分解成一系列的词法单元,也就是 Token。这些 Token 是代码的最小语法单元,包括关键字、标识符、操作符、常量等。词法分析器会按照一定的规则扫描源代码,并将其转换成一系列的 Token 序列。
下述代码为标准库中 Copy(稍有更改变量 src)
package main
import (
"fmt"
"go/scanner"
"go/token"
)
func main() {
// src is the input that we want to tokenize.
src := `
package main
import "fmt"
func main() {
fmt.Println("Hello, world")
}
`
// Initialize the scanner.
var s scanner.Scanner
fset := token.NewFileSet() // positions are relative to fset
file := fset.AddFile("", fset.Base(), len(src)) // register input "file"
s.Init(file, []byte(src), nil /* no error handler */, scanner.ScanComments)
// Repeated calls to Scan yield the token sequence found in the input.
for {
pos, tok, lit := s.Scan()
if tok == token.EOF {
break
}
fmt.Printf("%s\t%s\t%q\n", fset.Position(pos), tok, lit)
}
}
代码运行输出结果如下,其主要目的是将可读的代码转换为特定语法
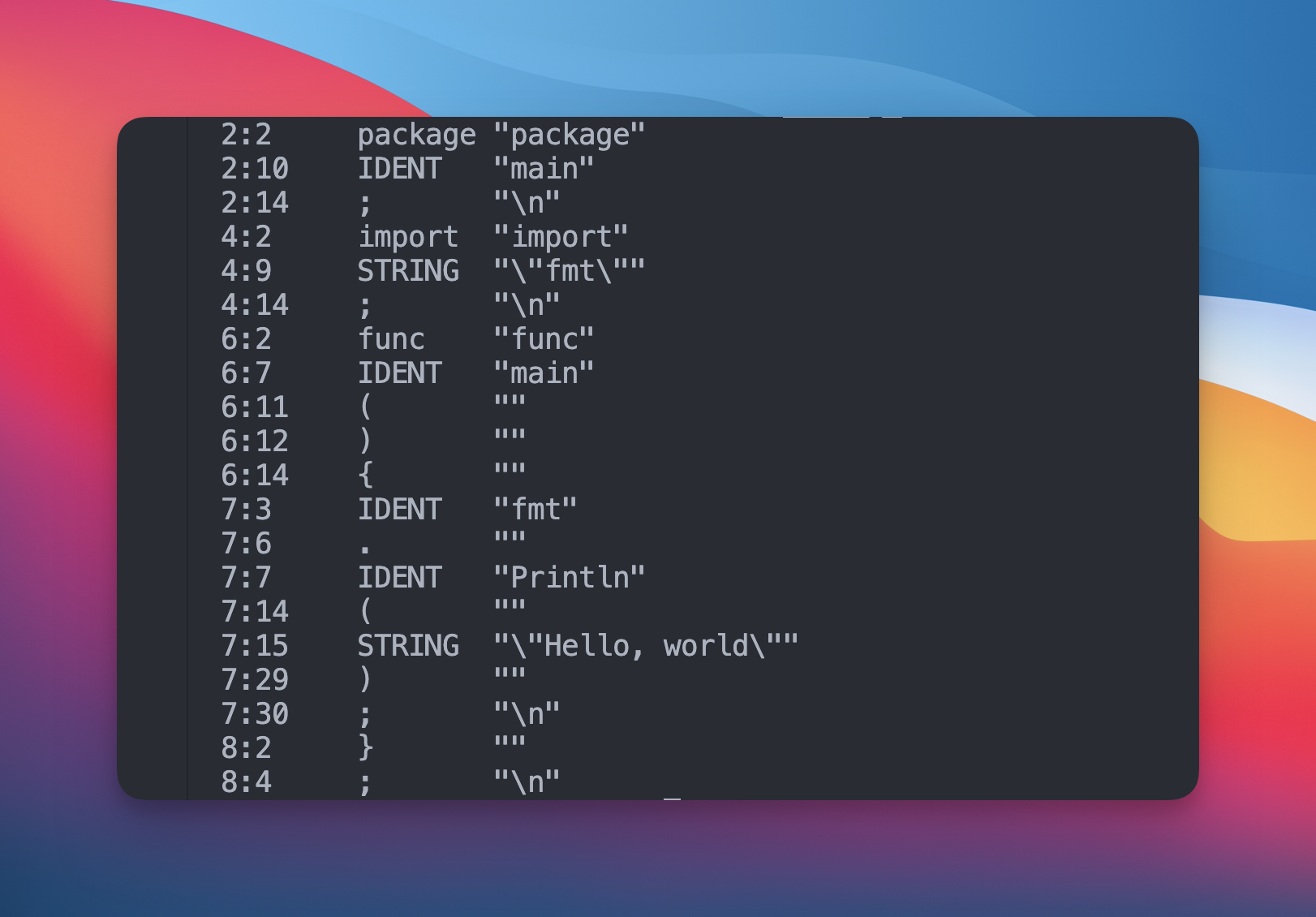
2、语法分析
Token 转换为 AST(Abstract Syntax Tree)
接下来便是从 Token 中继续解析为 AST 结构。我们从 ssa.html 中可以看到(从左上角,数着排列),第一个为 Source,也就是上述代码。紧接着就看到了 AST,这一部分是在词法分析中操作所生成的抽象语法树(AST)
当然,Golang 标准库也提供了主动输出 AST 结构,下面直接套用 AST 文档中的 Example (其中更改为fmt输出)
package main
import (
"go/ast"
"go/parser"
"go/token"
)
func main() {
// src is the input for which we want to print the AST.
src := `
package main
import "fmt"
func main() {
fmt.Println("Hello, world")
}
`
// Create the AST by parsing src.
fset := token.NewFileSet() // positions are relative to fset
f, err := parser.ParseFile(fset, "", src, 0)
if err != nil {
panic(err)
}
// Print the AST.
ast.Print(fset, f)
}
下图为上述代码执行的输出,顾名思义,生成结果是个树结构。通过与ssa.html文件中的 AST 版区输出比对,会发现还是有些区别,但大体结构是相同的,主旨在将代码梳理称为抽象语法树,从而方便语法分析步骤的进行。
![[Pasted image 20230527213338.png]]
从源码到Token,再到AST。我们不难发现,编译器所做的事情,是一步步将结构抽象化,从我们可读的源码转变,再经过一些列的分析,从而达到最终清洗的结构
在语法分析阶段,词法分析器生成的token序列会被转换成抽象语法树(AST)
在Go语言中,语法分析器使用递归下降算法来构建AST。递归下降算法是一种自顶向下的分析方法,它根据语法规则将代码解析成语法树。Go语言中的语法分析器会按照一定的顺序遍历token序列,并根据语法规则生成AST节点。
在AST中,每个节点代表一个语法结构,包括函数、变量、表达式等。语法分析器会根据语法规则生成相应的节点,并将它们组合成一棵树形结构。
3、类型检查
在生成AST之后,Go编译器会进行类型检查和代码生成等操作。类型检查器会对程序进行静态类型检查,确保所有的类型都是正确的。如果发现类型错误,类型检查器会报告错误信息。
在类型检查完成后,编译器会根据AST生成目标代码。Go语言的编译器采用静态单赋值(SSA)形式的中间代码表示,然后将其转换成机器码。最终生成的可执行文件可以在目标平台上运行。